
Natural Language Processing & Naive Bayes Classification of Real-time Twitter Streaming
People are getting crazy with Pokemon Go recently. I wonder what the result will be like to do an emotional analysis on the topic of #Pokemon Go# on Twitter.
Teenagers are wondering around along rivers and in parks to hunt. Grandma and Grandpa are driving out to catch rare ones. However, it is getting crazy. Some Pokemon fans are playing with their iPhones while driving on highway. As an engineer, I found it difficult to explain. While a lot of funny tweets burst out, I am expecting to find interesting things from these tweets.
In this blog, I will first build a web crawler to capture real-time tweets. Then tweets are filtered based on location and keywords, so that only tweets that contains keyword “Pokemon” and sent in US are left. Then I trained two Naive Bayes classifiers using two different corpus from nltk, the movie_reviews and twitter_samples, respectively. However, surprising results are found that the classifier trained by movie_reviews are more reliable, even the data sets are from Twitter. The analysis and visualization part are at the end of this blog.
Web Crawling for Real-Time Twitter Streaming
Here I use a Python library called tweepy for accessing the Twitter API. First of all, one must have access_token, and consumer_key to access the authorization. Then a StreamListener class will be buit to monitor the tweeter streaming. Any newly posted tweets will trigger the on_status function in this listener. Within this on_status function, one can do filtering, natural language processing and classification. To prevent overflow, one can either set a time limit or item number limit on the streaming.
Below is my Python code for the Tweeter API authorization part:
import tweepy
import time
import os
import sys
start_time = time.time()
time_limit=60
consumer_key="Enter your key here"
consumer_secret="Enter your secret here"
access_token="Enter your token here"
access_token_secret="Enter your secret here"
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
And then the StreamListener
tweets = []
save_file = open('13may.json', 'a')
class MyStreamListener(tweepy.StreamListener):
def __init__(self, api):
self.api = api or API()
super(tweepy.StreamListener, self).__init__()
self.save_file = tweets
self.n = 0
self.m = 200
def on_status(self, status):
if ('pokemon' in status.text.lower()):
print (status.text)
self.n = self.n+1
if self.n < self.m: return True
else:
print ('tweets = '+str(self.n))
return False
def on_error(self, status_code):
if status_code == 420:
#returning False in on_data disconnects the stream
print("error")
return False
myStreamListener = MyStreamListener(api)
myStream = tweepy.Stream(auth = api.auth, listener=myStreamListener)
key_filtered_stream=myStream.filter(locations=[-127.597019, 32.375215, -0.953617,48.152158])
Then all the filtered tweets are saved in a file named 13may.json.
Training the Naive Bayes Classifier for Emotional Analysis using Two Corpus
In this part, we use the movie_reviews and twitter_samples corpus to train our natural language Naive Bayes Classifier. The training procedure are the same, so I only show the one for movie_reviews below. This is a separated script named movieReviews.py, in a subfolder sentiment.
import nltk.classify.util
from nltk.classify import NaiveBayesClassifier
from nltk.corpus import movie_reviews
#import word_feats.word_feats as WF
import sentiment.word_feats.word_feats as WF
def movie_pos_neg_classifier():
negids = movie_reviews.fileids('neg')
posids = movie_reviews.fileids('pos')
negfeats = [(WF.word_feats(movie_reviews.words(fileids=[f])), 'neg') for f in negids]
posfeats = [(WF.word_feats(movie_reviews.words(fileids=[f])), 'pos') for f in posids]
negcutoff = int(len(negfeats)*3/4)
poscutoff = int(len(posfeats)*3/4)
trainfeats = negfeats[:negcutoff] + posfeats[:poscutoff]
testfeats = negfeats[negcutoff:] + posfeats[poscutoff:]
print ('train on %d instances, test on %d instances' % (len(trainfeats), len(testfeats)))
classifier = NaiveBayesClassifier.train(trainfeats)
print ('accuracy:', nltk.classify.util.accuracy(classifier, testfeats))
return classifier
movie_pos_neg_classifier().show_most_informative_features()
Now we have two classifiers ready for use on the real-time tweets on Pokemon Go.
Emotional Analysis of Real-time Twitter Streaming #Pokemon Go
With the datasets captured and two classifiers, we are going to implement the emotional analysis of these datasets with keyword #Pokemon#.
First, we call these two classifiers somewhere in the main function.
clf0=Movie.movie_pos_neg_classifier()
clf1=Twitt.twitter_pos_neg_classifier()
Within the initialization function of MyStreamListener, we add the following lines:
self.MoviePos=0
self.MovieNeg=0
self.TwittPos=0
self.TwittNeg=0
The on_status function in MyStreamListener is changed to incorporate the real-time classifiers.
def on_status(self, status):
if ('pokemon' in status.text.lower()):
print (status.text)
sentiment_result_0=clf0.classify(WF.word_feats(status.text.split()))
sentiment_result_1=clf1.classify(WF.word_feats(status.text.split()))
if (sentiment_result_0=='neg'):
self.MovieNeg=self.MovieNeg+1
if (sentiment_result_0=='pos'):
self.MoviePos=self.MoviePos+1
if (sentiment_result_1=='neg'):
self.TwittNeg=self.TwittNeg+1
if (sentiment_result_1=='pos'):
self.TwittPos=self.TwittPos+1
if (sentiment_result_0=='neg' and sentiment_result_1=='pos'):
print(sentiment_result_0,sentiment_result_1)
self.n = self.n+1
if self.n < self.m: return True
else:
print ('tweets = '+str(self.n))
return False
Word Stemming
Note that if the raw data fetched by tweepy API is a big mess. Each item include the useless information such as ID, time, source, stopwords, punctuations, and etc.
{"created_at":"Sun Jul 17 17:09:38 +0000 2016","id":754724754863423488,"id_str":"754724754863423488","text":"RT @OmgPokemonGo: when ur about to catch a rare pokemon but the game freezes https:\/\/t.co\/yAKyGRfFJK","source":"\u003ca href=\"https:\/\/about.twitter.com\/products\/tweetdeck\" rel=\"nofollow\"\u003eTweetDeck\u003c\/a
So I add a word stemming function called word_feats in the above script, to get rid of numbers, ID, time, stop words, and punctuations with NLTK, after tokenizing text with status.text.split(). A built-in stemmer called SnowballStemmer is used here.
from nltk.corpus import stopwords
from nltk.stem.snowball import SnowballStemmer
import string
###clean up punctuation, stopwords, numbers
def word_feats(words):
stemmer=SnowballStemmer("english")
stop = stopwords.words('english')
return dict([(stemmer.stem(word), True) for word in words if (word not in string.punctuation) and (word not in stop) and word.isdigit()==False])
Now a much cleaner version of real-time tweets will be saved, along with the emotional tendency classification in the file named 13may.json. Also, the number of emotionally positive tweets and emotionally positive tweets will be counted and recorded. Each item looks like this:
I'd like to set off an incense with a lucky egg next to a Pokestop with a lure so I can double my XP and level up to 11. #PokemonGO
Positive by moveie_review classifier
Negative by tweeter_samples classifier
Analysis and Visualization
I discovered that these classifiers trained by two different corpus generate many disparate classification results. So I intentionally collect 200 disparate classification samples for analysis, and manually classify them for validation. Tweets that are too neutral or controversial to decide are passed. Eventually, 100 manually classified samples are generated.
Eventually I use a visualization software called Tableau to have a deep look into the results.
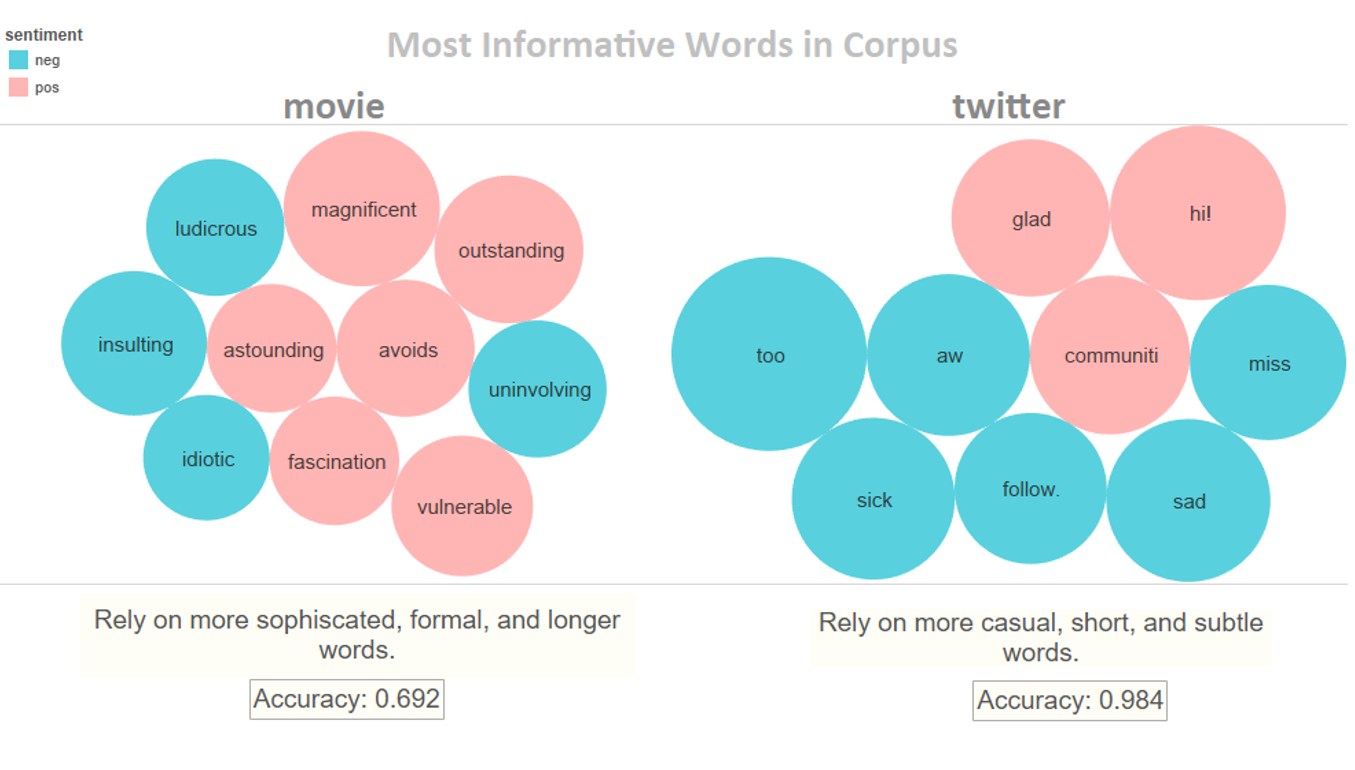
Most Informative Words for Classification
It seems that the classifier trained by movie_review corpus relies on more sophisticated, formal and longer words. While, the one trained by twitter_samples corpus relies on more casual, short, and subtle words.
An overview of the classification differences
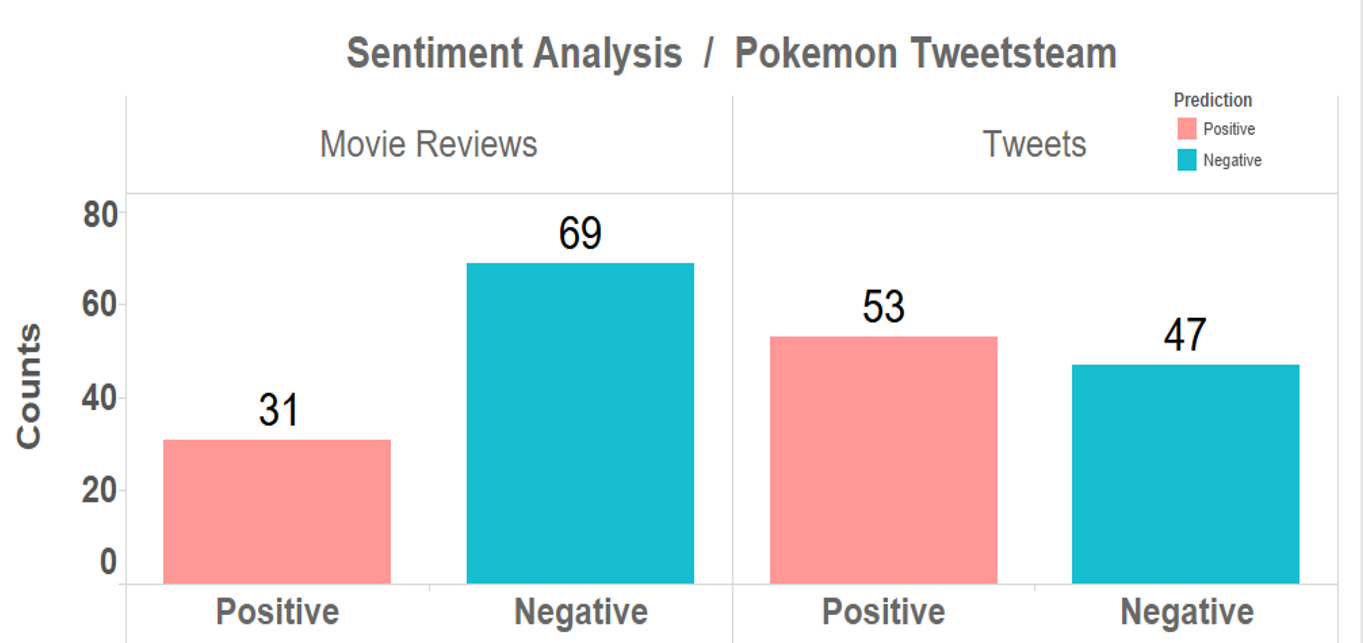
Conclusion
False prediction rates:
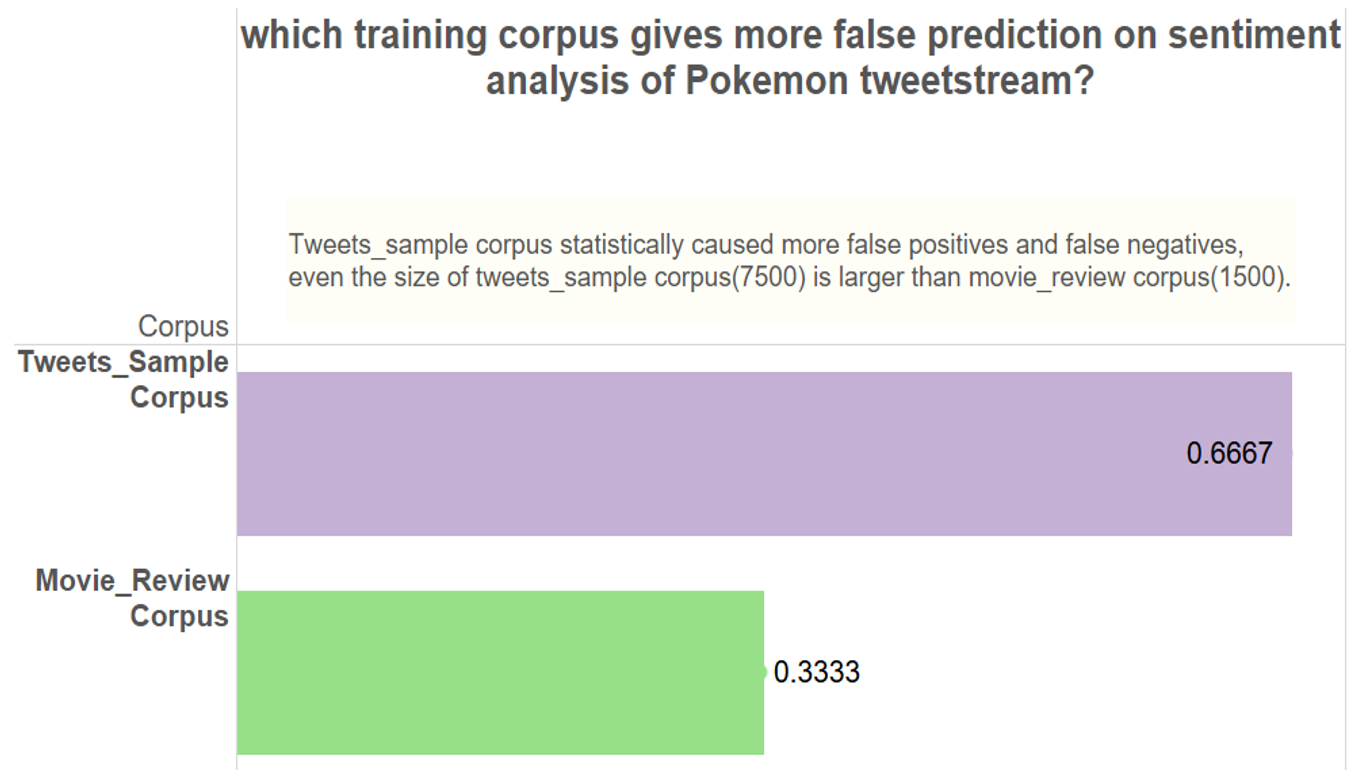
Pitfalls:
Please note that Movie_review corpus gives most false prediction on texts including movements, jointed words and abbreviations. Like go, walk, yield, NotExaggerating, Lol. And Tweeter_samples corpus gives more false prediction on texts including dirty words, which can actually be positive sometimes.